JDAO —— java持久层框架 [English]
简介:Jdao是一种创新的持久层解决方案。主要目的在于 减少编程量,提高生产力,提高性能,支持多数据源整合操作,支持数据读写分离,制定持久层编程规范。 灵活运用Jdao,可以在持久层设计上,减少30%甚至50%以上的编程量,同时形成持久层的统一编程规范,减少持久层错误,同时易于维护和扩展。
Jdao的映射模块实现了SQL与程序分离的特性,映射模块与myBatis的核心功能相同。是除了mybatis和基于myBatis系列的orm外,唯一实现该特性的orm框架.
GitHub : Jdao Repository
示例程序: Jdaodemo
使用文档: Jdaodoc
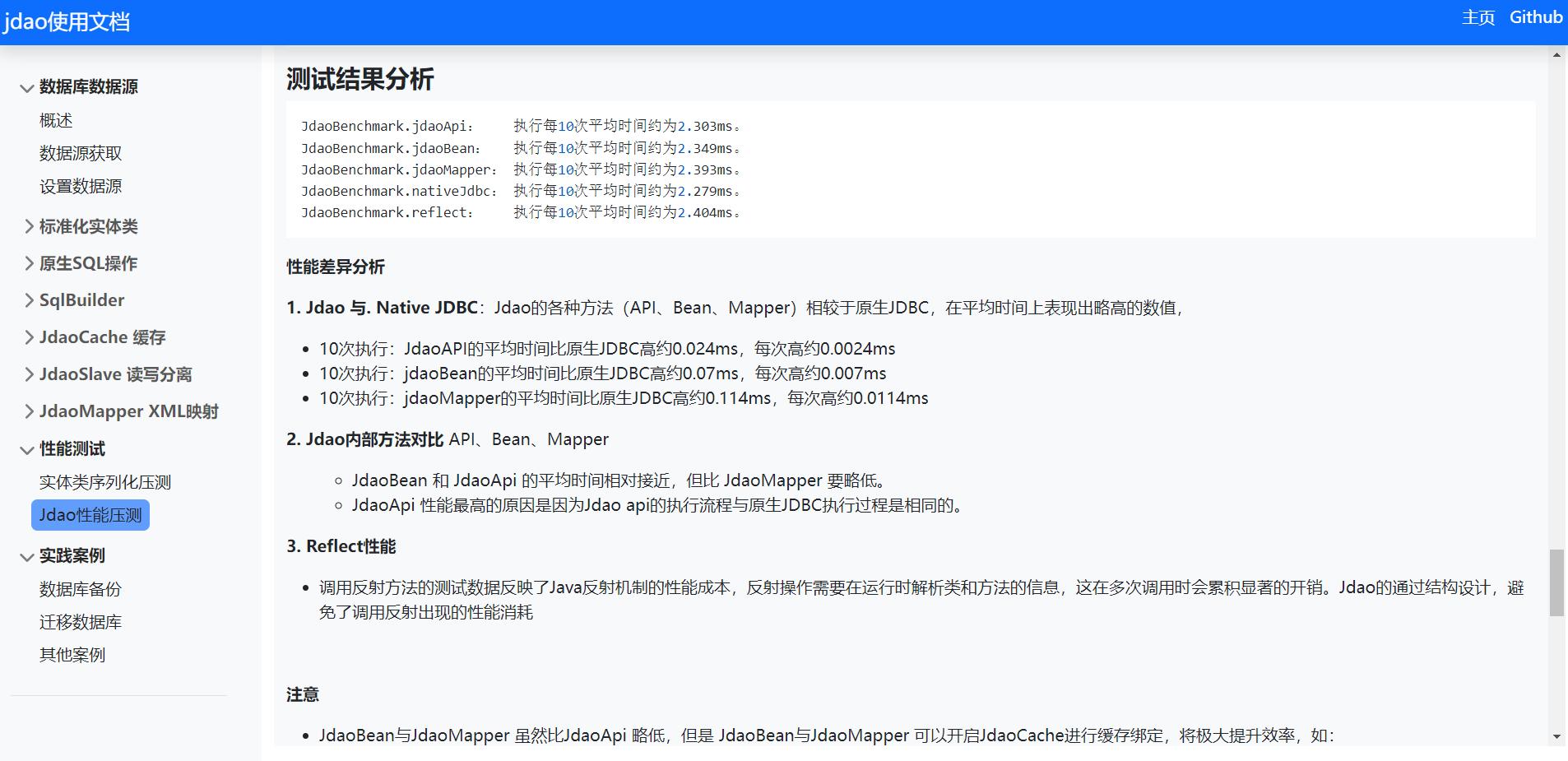
主要特点
- 轻量:Jdao没有任何依赖,所有特性均为Jdao本身实现,不会由于其他项目的更新或功能修改而受到影响,可以轻松融入各类项目中。
- 高效:Jdao功能均自身实现最重要目的就是实现高效性,没有多余的包袱。性能与直接JDBC调用极为接近,ORM封装的性能损耗非常小。
- 灵活:Jdao支持丰富的动态SQL构建功能,包括原生动态SQL,映射动态SQL,实体类动态SQL。
- 安全:Jdao没有SQL注入的风险。Jdao提供了Mybatis相同的映射功能,并去掉了sql注入的潜在隐患。
- 全面:Jdao结合了Hibernate的抽象性和MyBatis的灵活性,提供规范且高效的ORM运用方案。
主要功能
- 生成代码:运行jdao代码生成工具,创建数据库表的标准化实体类。类似thrift/protobuf。
- 高效序列化:表的标准化实体类实现了高效的序列化与反序列化。比标准库序列化方法高3-12倍,而序列化体积只有其20%左右。
- 支持数据读写分离:jdao支持绑定多数据源,并支持数据源绑定表,类,映射接口等属性。并支持数据读写分离
- 支持数据缓存:jdao支持数据缓存,并支持对缓存数据时效,与数据回收等特性进行细致控制
- 广泛兼容性:jdao理论上支持所有实现JDBC接口的数据库
- 高级特性:支持事务,存储过程,批处理等数据库操作
- 支持动态SQL:jdao实现了mybatis的动态sql功能,去掉了安全隐患及无实用特性。同时为原生SQL提供了编写动态SQL的特性。
- 兼容myBatis:jdao在映射模块中,采用了mybatis的标签定义,并实现了相同的功能特性。
解决Hibernate与MyBatis痛点的新方案
Hibernate普遍认为存在的问题
- 过度封装:hibernate提供了一层高级的抽象(包括HQL),这有助于开发者专注于业务逻辑而不是底层的SQL,这是一种更高级的编程模型 但它高度自动化虽然减少了对SQL的理解需求,同时却也掩盖底层数据库的具体行为,这可能导致性能瓶颈难以定位和优化
- 复杂性:配置和学习曲线陡峭,对于大型项目可能引入不必要的复杂度,尤其是当需要进行细粒度控制时。
- 性能问题:反射和代理机制在高并发场景下可能影响性能,尤其是在大规模数据处理时。
MyBatis 普遍认为存在的问题
- SQL的维护:MyBatis 提供了通过 XML 配置文件将 SQL 与 Java 代码分离的功能,这种方式提高了灵活性,使开发者可以直接编写和优化 SQL。然而,将所有 SQL 都与代码分离,可能会导致大量的SQL配置。这无疑增加了配置的复杂度和维护的工作量。特别是在团队协作环境中, 过多的SQL或Xml文件还可能引发版本管理和合并冲突的问题。
- 重复工作:在 MyBatis 中,每个 DAO 都需要编写相似的 SQL 语句和结果映射逻辑。这种重复性工作不仅增加了开发时间,还容易引入错误,导致代码维护的复杂性增加。尤其是在处理常见的 CRUD 操作时,重复编写相似的 SQL 语句显得非常低效。
JDAO 的创新解决方案
JDAO框架结合了Hibernate的抽象性和MyBatis的灵活性,旨在提供一个既强大又直观的持久层解决方案。
- 标准化映射实体类,处理单表CRUD操作:90%以上的数据库单表操作,可用通过实体类操作完成。这些对单表的增删改查操作,一般不涉及复杂的SQL优化,由实体类封装生成,可以减少错误率,更易于维护。 利用缓存,读写分离等机制,在优化持久层上,更为高效和方便 标准化实体类的数据操作格式并非简单的java对象函数的拼接,而是更类似SQL操作的对象化,使得操作上更加易于理解。
- 复杂SQL的执行:在实践中发现,复杂SQL,特别是多表关联的SQL,通常需要优化,这需要对表结构,表索引性质等数据库属性有所了解。 而将复杂SQL使用 java对象进行拼接,通常会增加理解上的难度。甚至,开发者都不知道对象拼接后的最终执行SQL是什么,这无疑增加了风险和维护难度。 因此Jdao在复杂SQL问题上,建议调用Jdao的CURD接口执行,Jdao提供了灵活的数据转换和高效的javaBean映射实现,可以避免过渡使用反射等耗时的操作。
- 兼容myBatis映射文件: 对于复杂的sql操作,jdao提供了相应的crud接口。同时也支持通过xml配置sql进行接口映射调用,这点与mybatis特性相似,区别在于mybatis需要映射所有SQL操作。 而Jdao虽然提供了完整的sql映射接口,但是建议只映射复杂SQL,或操作部分标准实体类无法完成的CURD操作。 jdao的SQL配置文件参考mybatis配置文件格式,实现自己新的解析器,使得配置参数在类型的容忍度上更高,更灵活。
Jdao的强大之处:
Jdao通过提供多样化的解决方案来适应不同项目的需求;而同一个项目中,不同业务模块的持久层复杂度同样有区别,需要分而治之。比如项目中有大量简单的单表增删改查操作,如果都使用SQL映射,将出现大量类似的重复SQL与大量的XML配置文件。此时,用Jdao标准化实体类是最好的解决方案。反之,Jdao提供了SqlBuilder,Mapper等方式,来解决更为复杂数据场景。
jdao的强大之处在于,它考虑的项目中出现的各种情况,并分别给出了合适的解决方案,不同场景采用不同的方式解决问题,而不是用同一套方案解决所有问题,用同一套方案解决所有问题将又出现hibernate或mybatis出现的问题。 因此Jdao即适合小型项目,同时也适合大型项目,即适合小团队,也适合大团队。
Jdao的定位
Jdao的定位与hibernate,mybatis相似,希望提供一个灵活且可扩展的基础框架。与MyBatis-Plus这样的扩展性框架有所区别,扩展性框架通常为了满足那些寻求更高生产力和更快速开发的开发者们的需求。但是,它们增加的功能并不是所有项目都需要的,特别是对于那些已经有成熟架构和复杂业务逻辑的应用来说,可能更倾向于自己控制每一个细节。类似Jdao,Hibernate和MyBatis这些框架,设计的初衷是为了解决不同场景下的数据访问问题,它们提供了基础的CRUD操作以及映射机制来简化数据库交互过程,不内置过多的高级功能,保持了较好的可扩展性。
快速开始
安装 jdao依赖包
# 使用 Maven 安装
<dependency>
<groupId>io.github.donnie4w</groupId>
<artifactId>jdao</artifactId>
<version>2.1.0</version>
</dependency>Jdao 普通使用示例
数据源初始化
static {
Jdao.init(DataSourceFactory.getDataSourceBySqlite(), DBType.SQLITE); //初始化数据源,第一个参数是DataSource,第二是参数是数据库类型
Jdao.setLogger(true); // 测试环境打开Jdao日志打印,将输出执行的SQL即参数等信息
}标准化实体类增删改查
// 查询
Hstest t = new Hstest();
t.where(Hstest.ID.GT(1));
t.limit(20,10);
Hstest rs = t.select()// 更新
Hstest t = new Hstest();
t.SetValue("hello world")
t.where(Hstest.ID.EQ(1));
t.update()// 删除
Hstest t = new Hstest();
t.where(Hstest.ID.EQ(1));
t.delete()//新增
Hstest hs = new Hstest();
hs.setRowname("hello world");
hs.setValue("123456789");
hs.insert();原生SQL操作
//查询
Hstest hs = Jdao.executeQuery(Hstest.class,"select * from Hstest order by id desc limit ?",1);
System.out.println(hs);//新增
int i = Jdao.executeUpdate("insert into hstest2(rowname,value) values(?,?)", "helloWorld", "123456789");//更新
int i = Jdao.executeUpdate("update hstest set value=? where id=?", "hello",1);//插入
int i = Jdao.executeUpdate("delete from hstest where id = ?", 1);缓存操作
// 绑定Hstest.class 启用缓存
JdaoCache.bindClass(Hstest.class);读写分离
//读写分离绑定
JdaoSlave.bindClass(Hstest.class, DataSourceFactory.getDataSourceByPostgreSql(), DBType.POSTGRESQL);SQL映射
示例程序1
<select id="selectHstestById" resultType="io.github.donnie4w.jdao.dao.Hstest">
SELECT * FROM hstest WHERE id < #{id} and age < #{age}
</select> @Test
public void selectOne() throws JdaoException, JdaoClassException, SQLException {
Hstest hs = jdaoMapper.selectOne("io.github.donnie4w.jdao.action.Mapperface.selectHstestById", 2, 26);
System.out.println(hs);
}示例程序2
<select id="demo1" resultType="io.github.donnie4w.jdao.dao.Hstest">
SELECT * FROM hstest
<where>
<if test="rowname!= 'hello'">
and rowname = #{rowname}
</if>
<if test="id >0">
AND id = #{id}
</if>
</where>
</select> @Test
public void demo1() throws JdaoException, JdaoClassException, SQLException {
Hstest hs = new Hstest();
hs.setId(31);
hs.setRowname("hello");
List<Hstest> listSlave = jdaoMapper.selectList("io.github.donnie4w.jdao.action.Dynamic.demo1", hs);
for (Hstest hstest : listSlave) {
System.out.println(hstest);
}
}
SqlBuilder动态SQL
@Test
public void testAppendIf() throws JdaoException, SQLException {
Map<String, Object> context = new HashMap<>();
context.put("id", 31);
SqlBuilder builder = SqlBuilder.newInstance();
builder.append("SELECT * FROM HSTEST where 1=1")
.appendIf("id>0", context, "and id=?", context.get("id")) //若表达式id>0成立, 添加SQL : and id=?
.append("ORDER BY id ASC");
List<DataBean> list = builder.selectList();
for (DataBean bean : list) {
System.out.println(bean);
}
}