WFS文件存储系统,主要解决海量小文件的存储问题 [English]
wfs有非常高效的读写效率,在高并发压力下,wfs存储引擎读写响应时间可以达到微秒级别.
海量小文件可能带来的许多问题:
海量小文件存储在不同的硬件环境和系统架构下,都会带来一系列显著的问题。无论是采用传统的机械硬盘(HDD)还是现代的固态硬盘(SSD),这些问题都可能影响系统的性能、效率、扩展性和成本:
- 存储效率低下:对于任何类型的硬盘,小文件通常会导致物理存储空间的低效使用。由于硬盘有其最小存储单元(扇区或页),小文件可能会占用超过其实际内容大小的空间,尤其是在每个文件还需额外存储元数据的情况下,如inode(在Unix-like系统中)或其他形式的元数据记录,这会进一步加大空间浪费。inode耗尽:每个文件和目录至少占用一个inode,而inode的数量是在格式化磁盘并创建文件系统时预先设定的。当系统中有大量小文件时,即使硬盘空间还很充足,也可能因为inode用完而导致无法继续创建新文件,尽管剩余磁盘空间足以存放更多数据。性能影响:随着inode数量增多,查找和管理这些inode所对应的元数据会变得更复杂和耗时,尤其是对于不支持高效索引机制的传统文件系统,这会影响文件系统的整体性能。扩展性受限:文件系统设计时通常有一个固定的inode总数,除非通过特殊手段(如调整文件系统或重新格式化时指定更多inode),否则无法动态增加inode数量来适应小文件增长的需求。
- I/O性能瓶颈与资源消耗:在HDD环境中,随机读写大量小文件会引发频繁的磁盘寻道操作,从而降低整体I/O性能。而在SSD中,尽管寻道时间几乎可以忽略,但过于密集的小文件访问仍可能导致控制器压力增大、写入放大效应以及垃圾回收机制负担加重。
- 索引与查询效率问题:海量小文件对文件系统的索引结构形成挑战,随着文件数量的增长,查找、更新和删除小文件时所需的元数据操作会变得非常耗时。尤其在需要快速检索和分析场景下,传统索引方法难以提供高效的查询服务。
- 备份恢复复杂性与效率:备份海量小文件是一个繁琐且耗时的过程,同时在恢复过程中,尤其是按需恢复单个文件时,需要从大量备份数据中定位目标文件,这将极大地影响恢复速度和效率。
- 扩展性与可用性挑战:存储系统在处理海量小文件时,可能面临扩展性难题。随着文件数量的增长,如何有效分配和管理资源以维持良好的性能和稳定性是一大考验。在分布式存储系统中,还可能出现热点问题,导致部分节点负载过高,影响整个系统的稳定性和可用性。
wfs 作用在于将海量提交存储的小文件进行高效的压缩归档。并提供简洁的数据获取方式,以及后台文件管理,文件碎片整理等。
互联网大量小文件常见场景
- 社交媒体与图片分享:
- Facebook:Facebook每天有数十亿用户上传照片和视频,平均每个用户上传的照片数量达到数百张。因此,Facebook存储的图片数量达到数十亿甚至数百亿级别。为了满足这种海量小文件的存储需求,Facebook推出了Haystack系统来优化存储效率和访问速度。
- Instagram:另一个流行的社交媒体平台,用户每天上传数亿张照片和视频。这些文件通常较小,但数量巨大,因此需要高效的存储和访问机制
- 电子商务与商品展示:
- 亚马逊:作为全球最大的电子商务平台之一,亚马逊拥有数亿个商品列表,每个商品通常都有多张图片。据统计,亚马逊每天处理的图片数量达到数十亿张,这些图片文件虽然单个较小,但总体数量庞大,对存储系统提出了巨大的挑战。
- 淘宝:作为中国最大的电子商务网站之一,淘宝存储了数十亿计的商品图片,其中大部分是小文件。淘宝针对这些图片推出了优化的文件系统,以提高存储效率和访问速度
- 在线视频与流媒体:
- Netflix:作为领先的在线视频服务提供商,Netflix拥有庞大的视频库,每天有数以亿计的用户观看视频内容。在流媒体传输过程中,视频文件通常会被切割成较小的分片文件以适应不同的网络条件。因此,Netflix需要处理的小文件数量也非常庞大,这要求其存储系统具有高效的读写性能和扩展性。
- 高性能计算与科研数据:
- 科研实验室:在科研领域,随着技术的发展,实验数据的生成速度越来越快。例如,在基因测序领域,一个实验室每天可能产生数TB甚至数十TB的测序数据,这些数据通常以多个小文件的形式存在。因此,科研实验室对于小文件的存储和管理也有着巨大的需求。
- 超级计算机:在进行大规模科学计算和模拟时,超级计算机会产生海量的中间结果和输出文件,其中许多都是较小的文件。这些文件的存储和管理对于保持计算效率至关重要
- 金融与票据影像:
- 大型银行:大型银行每天处理的票据数量达到数百万张,这些票据通常会被扫描成图片并存储。以每张票据平均生成几个图片文件计算,一个大型银行每天需要存储的小图片文件数量就可能达到数千万张甚至更多。这些图片文件虽然单个大小不大,但总体规模庞大,对存储系统的稳定性和性能提出了很高的要求。
- 在线教育与内容分享:
- Coursera、网易云课堂等在线教育平台需要存储大量的课程资料,包括教学视频、PPT、图片等,其中很多也是小文件。
- 知乎、豆瓣 等社区平台,用户上传的头像、回答中的图片等也是小文件存储的常见场景
- 短信/即时通讯服务:
- 在短信和即时通讯服务如 微信、WhatsApp等应用中,用户发送的文字消息、表情包、语音片段、位置信息等都属于小文件。尤其在群聊中,短时间内会产生大量的小文件数据。这类应用背后的存储系统必须具备高效处理大量小文件的能力,保证实时性和高并发请求的响应速度。
- Web托管与CDN服务:
- 在网站托管和内容分发网络(CDN)中,网页元素(如CSS样式表、JavaScript脚本、小图标等)都是小文件,一个大型网站可能会包含上万个这样的小文件。为了提供快速加载和高可用的服务,服务商需要对这些小文件进行高效存储和缓存管理,比如使用HTTP/2协议的服务器推送、资源合并与压缩等技术,以减少请求数量并提高传输效率。
- 基因测序数据处理:
- 在生物信息学领域,基因测序产生的原始数据由无数个短序列片段组成,每个片段可以看作一个小文件。整个基因组的数据量非常庞大,往往涉及数百万乃至数十亿个小文件。基因测序数据中心需要高性能的存储系统来支撑数据的快速存取和分析,如采用分布式存储系统结合索引结构来应对大量小文件问题。
数据大致展示了小文件应用场景的规模和重要性,同时也说明了为什么这些领域对于高效的小文件存储和处理有着迫切的需求。随着技术的发展和数据量的不断增长,这种需求还将继续增加。
在大量小文件应用场景下,wfs实现的关键技术包括以下几个方面
- 高效存储布局与合并技术: WFS将多个小文件聚合成大文件存储,以减少元数据开销和提高存储利用率。同时,通过灵活的索引机制,确保每个小文件都能快速定位和提取。
- 分布式存储架构:wfs1.x版本主要聚焦性能提升来满足特定应用场景的需求,并建议通过第三方负载均衡分发技术如nginx,实现横向扩展节点数量来应对海量小文件的存储需求,确保系统在高并发场景下的稳定性和性能表现。
- 元数据管理优化: 针对大量小文件元数据管理难题,wfs采用高效元数据索引和缓存策略,减少元数据查询时间,并采用层级目录结构或哈希索引等方法,降低元数据存储的复杂度。
- 缓存与预读策略: 引入lru缓存机制,对访问频繁的数据进行缓存,降低I/O操作次数,提高读取速度。
- 数据去重与压缩技术: 实现数据去重和数据压缩,去除重复内容,减小存储空间占用,并通过多级压缩算法优化存储效率。
- 高可用与容错设计: 支持元数据导出与数据导入,确保在发生故障时,可以快速恢复数据,保证系统服务的持续性和数据完整性。
应用场景
- 海量非结构化数据存储:适用于存储大量的非结构化数据,如图片、视频、日志文件、 备份数据、静态资源文件等。
- 高效文件数据读取:wfs存储引擎可以达到100万/每秒 以上的数据读取效率,特别适合文件读取密集型的业务。
- 多种图片处理需求:wfs内置图片基础处理,适合对图片处理多种要求的业务,如图片适应多个尺寸,自定义裁剪等。
wfs相关程序
- wfs源码地址 https://github.com/donnie4w/wfs
- go客户端 https://github.com/donnie4w/wfs-goclient
- rust客户端 https://github.com/donnie4w/wfs-rsclient
- java客户端 https://github.com/donnie4w/wfs-jclient
- python客户端 https://github.com/donnie4w/wfs-pyclient
- wfs在线体验 http://testwfs.tlnet.top 用户名 admin 密码 123
- wfs使用文档 https://tlnet.top/wfsdoc
- 下载地址 https://tlnet.top/download
docker镜像
docker pull donnie4w/wfs
wfs的特点
- 高效性
- 简易性
- 零依赖
- 界面管理
- 图片处理
- 文件处理
WFS的压力测试与性能评估
请注意,以下基准测试数据主要针对WFS数据存储引擎,未考虑网络因素的影响。在理想条件下,基于基准测试数据得出估算数据
以下为部分压测数据截图



测试数据说明:
- 第一列为测试方法,写Append, 读Get , *-4四核,*-8八核
- 第二列为本轮测试执行总次数
- ns/op: 每执行一次消耗的时间
- B/op:每执行一次消耗的内存
- allocs/op:每执行一次分配内存次数
根据基准测试数据,可以估算出wfs存储引擎的性能
- 存储数据性能估算
- Benchmark_Append-4 平均每秒执行的操作次数约为:1 / (36489 ns/operation) ≈ 27405次/s
- Benchmark_Append-8 平均每秒执行的操作次数约为:1 / (31303 ns/operation) ≈ 31945次/s
- Benchmark_Append-4 平均每秒执行的操作次数约为:1 / (29300 ns/operation) ≈ 34129次/s
- Benchmark_Append-8 平均每秒执行的操作次数约为:1 / (24042 ns/operation) ≈ 41593次/s
- Benchmark_Append-4 平均每秒执行的操作次数约为:1 / (30784 ns/operation) ≈ 32484次/s
- Benchmark_Append-8 平均每秒执行的操作次数约为:1 / (30966 ns/operation) ≈ 32293次/s
- Benchmark_Append-4 平均每秒执行的操作次数约为:1 / (35859 ns/operation) ≈ 27920次/s
- Benchmark_Append-8 平均每秒执行的操作次数约为:1 / (33821 ns/operation) ≈ 29550次/s
- 获取数据性能估算
- Benchmark_Get-4 平均每秒执行的操作次数约为:1 / (921 ns/operation) ≈ 1085776次/s
- Benchmark_Get-8 平均每秒执行的操作次数约为:1 / (636 ns/operation) ≈ 1572327次/s
- Benchmark_Get-4 平均每秒执行的操作次数约为:1 / (1558 ns/operation) ≈ 641848次/s
- Benchmark_Get-8 平均每秒执行的操作次数约为:1 / (1296 ns/operation) ≈ 771604次/s
- Benchmark_Get-4 平均每秒执行的操作次数约为:1 / (1695 ns/operation) ≈ 589970次/s
- Benchmark_Get-8 平均每秒执行的操作次数约为:1 / (1402ns/operation) ≈ 713266次/s
- Benchmark_Get-4 平均每秒执行的操作次数约为:1 / (1865 ns/operation) ≈ 536000次/s
- Benchmark_Get-8 平均每秒执行的操作次数约为:1 / (1730 ns/operation) ≈ 578034次/s
写入数据性能
- 在不同并发条件下,WFS存储引擎的写入操作平均每秒执行次数介于约 3万次/s 至 4万次/s 之间。
读取数据性能
- WFS存储引擎读数据操作的性能更为出色,平均每秒执行次数在 53万次/s 至 150万次/s 之间。
请注意:测试结果与环境有很大关系。实际应用中的性能可能会受到多种因素的影响,如系统负载、网络状况、磁盘I/O性能等,实际部署时需要根据具体环境进行验证和调优。
wfs内置图片基础处理
原图: https://tlnet.top/statics/test/wfs_test.jpg

- 裁剪正中部分,等比缩小生成200x200缩略图 https://tlnet.top/statics/test/wfs_test.jpg?imageView2/1/w/200/h/200

- 宽度固定为200px,高度等比缩小,生成宽200缩略图 https://tlnet.top/statics/test/wfs_test.jpg?imageView2/2/w/200

- 高度固定为200px,宽度等比缩小,生成高200缩略图 https://tlnet.top/statics/test/wfs_test.jpg?imageView2/2/h/200

- 高斯模糊,生成模糊程度Sigma为5,宽200的图片 https://tlnet.top/statics/test/wfs_test.jpg?imageView2/2/w/200/blur/5

- 灰色图片,生成灰色,宽200的图片 https://tlnet.top/statics/test/wfs_test.jpg?imageView2/2/w/200/grey/1

- 颜色反转,生成颜色相反,宽200的图片 https://tlnet.top/statics/test/wfs_test.jpg?imageView2/2/w/200/invert/1

- 水平反转 ,生成水平反转,宽200的图片 https://tlnet.top/statics/test/wfs_test.jpg?imageView2/2/w/200/fliph/1

- 垂直反转 ,生成垂直反转,宽200的图片 https://tlnet.top/statics/test/wfs_test.jpg?imageView2/2/w/200/flipv/1

- 图片旋转 ,生成向左旋转45度,宽200的图片 https://tlnet.top/statics/test/wfs_test.jpg?imageView2/2/w/200/rotate/45

- 格式转换 ,生成向左旋转45,宽200的png图片 https://tlnet.top/statics/test/wfs_test.jpg?imageView2/2/w/200/rotate/45/format/png

图片处理方式见 wfs使用文档
WFS的使用简单说明
- 执行文件下载地址:https://tlnet.top/download
- 启动:
./linux101_wfs -c wfs.json
3. wfs.json 配置说明
{
"listen": 4660,
"opaddr": ":6802",
"webaddr": ":6801",
"memLimit": 128,
"data.maxsize": 10000,
"filesize": 100,
}属性说明:
- listen http/https 资源获取服务监听端口
- opaddr thrift后端资源操作地址
- webaddr 管理后台服务地址
- memLimit wfs内存最大分配 (单位:MB)
- data.maxsize wfs上传图片大小上限 (单位:KB)
- filesize wfs后端归档文件大小上限 (单位:MB)
wfs使用详细说明请参考 wfs使用文档
WFS如何存储,删除数据
1. http/https
curl -F "file=@1.jpg" "http://127.0.0.1:6801/append/test/1.jpg" -H "username:admin" -H "password:123"
curl -X DELETE "http://127.0.0.1:6801/delete/test/1.jpg" -H "username:admin" -H "password:123"
2. 使用客户端
以下是java客户端 示例
public void append() throws WfsException, IOException {
String dir = System.getProperty("user.dir") + "/src/test/java/io/github/donnie4w/wfs/test/";
WfsClient wc = newClient();
WfsFile wf = new WfsFile();
wf.setName("test/java/1.jpeg");
wf.setData(Files.readAllBytes(Paths.get(dir + "1.jpeg")));
wc.append(wf);
}3. 通过管理后台上传/删除文件
WFS管理后台
默认搜索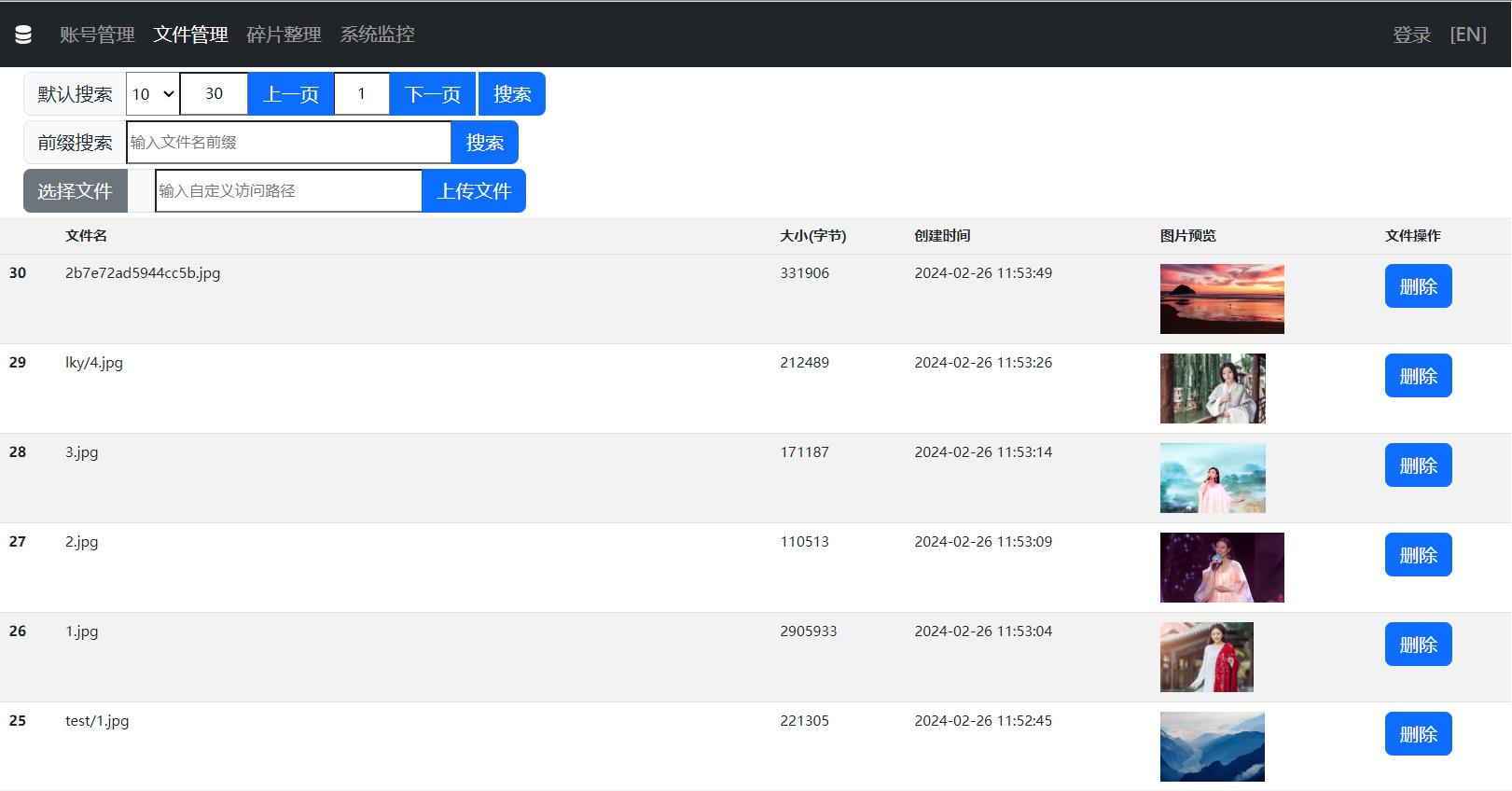
前缀搜索
碎片整理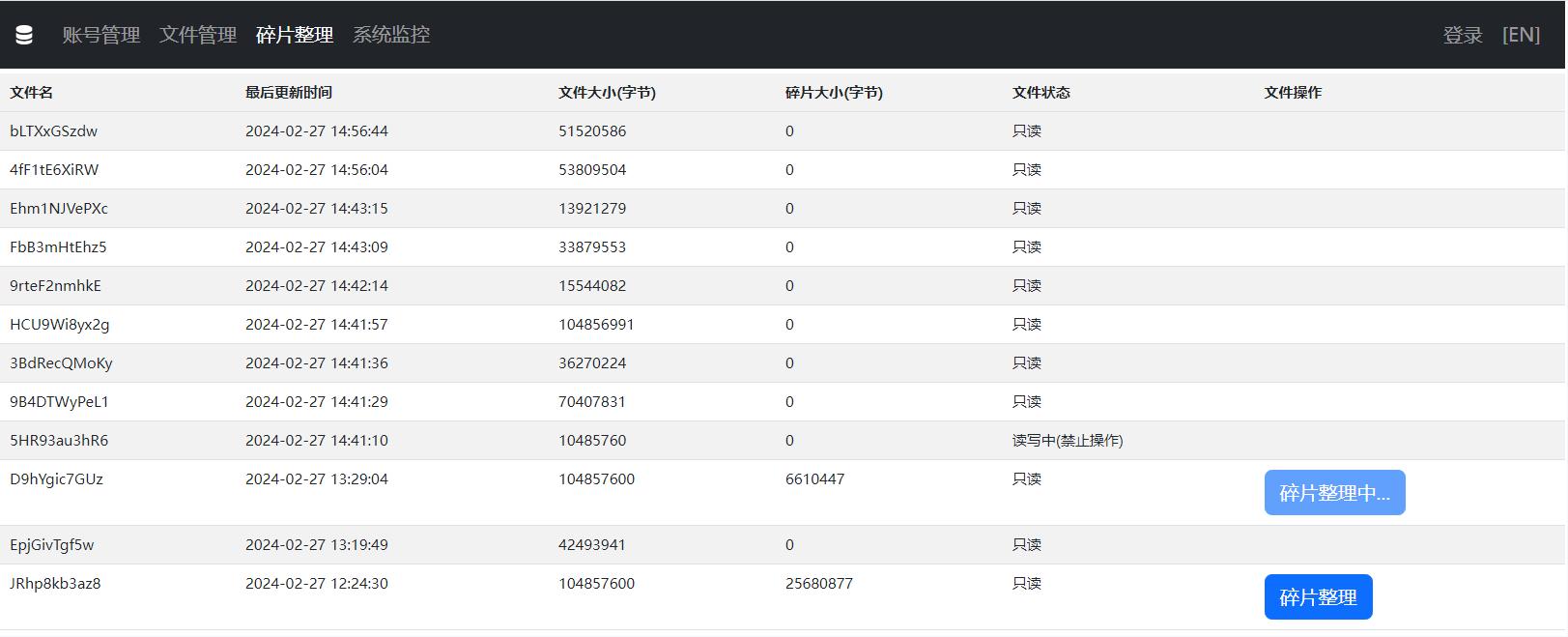
WFS的分布式部署方案
wfs0.x版本到wfs1.x版本的设计变更说明:wfs0.x 版本实现了分布式存储,这使得系统能够跨多个服务器分散存储和处理数据,具备水平扩展能力和数据备份冗余能力,但是在实际应用中也暴露出一些问题,如元数据重复存储导致空间利用率不高。对于小文件的处理效率低,因为在节点间频繁转发传输,造成系统资源消耗增加。
wfs1.x版本的目标在于通过精简架构、聚焦性能提升来满足特定应用场景的需求,而在分布式部署方面的考量则交由用户借助第三方工具和服务来实现。
- wfs1.x不直接支持分布式存储,但为了应对大规模部署和高可用需求,推荐采用如Nginx这样的负载均衡服务,通过合理的资源配置和定位策略,可以在逻辑上模拟出类似分布式的效果。也就是说,虽然每个wfs实例都是单机存储,但可以通过外部服务实现多个wfs实例之间的请求分发,从而达到业务层面的“分布式部署”。如何实现wfs的“分布式部署”可以参考文章《WFS的分布式部署方案》
- 必须说明的是,超大规模数据存储业务中,分布式系统确实具有显著优势,包括动态资源调配、数据分块存储、多节点备份等高级功能。然而,分布式采用负载均衡策略的wfs1.x,则需要用户自行采取措施保证数据安全性和高可用性,例如定期备份数据、搭建负载均衡集群,并且在应用程序中配置并设计路由规则,确保数据能正确地路由到目标节点。
- wfs的优势在于其简洁性和高效性。实际上,并非任何文件存储业务都需要复杂的分布式文件系统,相反,大部分业务尚未达到超大规模的量级,而使用复杂的分布式文件系统可能会带来与之不相匹配的过多额外成本和运维难度。目前的wfs及其相应的分布式部署策略已经能够较好地满足各种业务需求。