B+树(英语:B+ tree)是一种树数据结构,通常用于数据库和操作系统的文件系统中。B+树的特点是能够保持数据稳定有序,其插入与修改拥有较稳定的对数时间复杂度。B+树元素自底向上插入,这与二叉树恰好相反。
B+树在节点访问时间远远超过节点内部访问时间的时候,比可作为替代的实现有着实在的优势。这通常在多数节点在次级存储比如硬盘中的时候出现。通过最大化在每个内部节点内的子节点的数目减少树的高度,平衡操作不经常发生,而且效率增加了。这种价值得以确立通常需要每个节点在次级存储中占据完整的磁盘块或近似的大小。
| 算法 | 平均 | 最差 | |
|---|---|---|---|
| 空间 | O(n) | O(n) | |
| 搜索 | O(logn) | O(logn) | |
| 插入 | O(logn) | O(logn) | |
| 删除 | O(logn) | O(logn) |
B+树背后的想法是内部节点可以有在预定范围内的可变量目的子节点。因此,B+树不需要像其他自平衡二叉查找树那样经常的重新平衡。对于特定的实现在子节点数目上的低和高边界是固定的。例如,在 2-3 B 树(常简称为2-3 树)中,每个内部节点只可能有 2 或 3 个子节点。如果节点有无效数目的子节点则被当作处于违规状态。
B+树的创造者Rudolf Bayer没有解释“B”的意义,最常见的观点是代表“平衡”(balanced)或其名字“Bayer”。
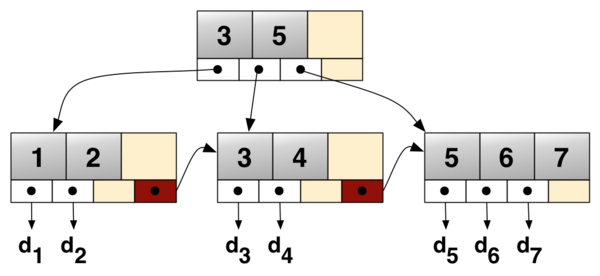
节点结构
在B+树中的节点通常被表示为一组有序的元素和子指针。如果此B+树的阶数是m,则除了根之外的每个节点都包含最少 ⌊m/2⌋ 个元素最多 m−1 个元素,对于任意的结点有最多 m 个子指针。对于所有内部节点,子指针的数目总是比元素的数目多一个。所有叶子都在相同的高度上,叶结点本身按关键字大小从小到大链接。
算法
查找
查找以典型的方式进行,类似于二叉查找树。起始于根节点,自顶向下遍历树,选择其分离值在要查找值的任意一边的子指针。在节点内部典型的使用是二分查找来确定这个位置。
插入
节点要处于违规状态,它必须包含在可接受范围之外数目的元素。
- 首先,查找要插入其中的节点的位置。接着把值插入这个节点中。
- 如果没有节点处于违规状态则处理结束。
- 如果某个节点有过多元素,则把它分裂为两个节点,每个都有最小数目的元素。在树上递归向上继续这个处理直到到达根节点,如果根节点被分裂,则建立一个新根节点。为了使它工作,元素的最小和最大数目典型的必须选择为使最小数不小于最大数的一半。
删除
- 首先,查找要删除的值。接着从包含它的节点中删除这个值。
- 如果没有节点处于违规状态则处理结束。
- 如果节点处于违规状态则有两种可能情况:
注解
假定 L是节点允许拥有子节点的最小数目,而 U 是最大数目。则每个节点总是有在 L和U 之间(包含它们在内)个子节点,除了一个例外:根节点有从2 到 U(包含它们在内)个子节点。换句话说,根节点豁免于低边界限制,而拥有它自己的低边界2。这允许树持有小数目的元素。根有一个子节点没有意义,因为附着在这个子节点上的子树可以简单的附着在根节点上。允许根节点没有子节点也是不需要的,因为没有元素的树典型的表示为没有根节点。
Robert Tarjan 证明了均摊的分裂/合并数目是 2。