前言
实现共识算法是一项复杂的任务,它不仅要求合适的数据结构、缓存机制、压缩技术以及通讯优化等技术支持,还需要构建一个高效、低负载、支持高并发和高吞吐量的协议交互过程。更为关键的是,必须设计出严谨的交互逻辑,考虑所有可能出现的情况,并提供合理的应对策略,以防止意外情况导致系统错误。
raft,multi-paxos,zab等协同协议作为paoxs的简化版本,对于当前的计算机系统,更易于落地实现,它们协议逻辑同样可靠。
paxos协议为什么那么难实现,主要在于Paxos 是基于分布式系统理论设计的, 它并非是基于现有计算机通讯的实际场景的抽象理论,它依赖一些理想化的假设(如网络可靠性、同步模型等),它的正确性依赖于严格的数学证明 ,它的理想模型与现实情况是有差异的;数学模型与代码的映射是个难点:如何将复杂的数学模型(如Paxos的证明中的“多数原则”)转化为代码中的逻辑是一个巨大的挑战。理论上的证明无法直接转化为具体的编程细节,开发者需要根据理论设计出正确的算法,并通过测试和调试来验证其正确性 ;另外paxos专注于一致性,而不是性能或可扩展性,比如它需要多个通信轮次来达成共识;理论上,只要大多数节点达成一致,系统就可以继续运作。但现实中,系统如果没有性能保证时,几乎就没有了实用价值。
raft之所以应用广泛,是它把算法模型与实际计算机通讯系统的特性挂钩,算法流程都可以有相应程序实现方式。但是raft的简易性也同时是它的局限性,它依赖于事务的串行执行,也就是它将并行的提案排队,一个一个处理,形成有序的日志,这样让算法变得十分简单,许多并行事件可能出现问题,在raft系统中将不会出现,比如所有节点都出现缺数据的问题,而raft中多数派节点始终是完整的数据。
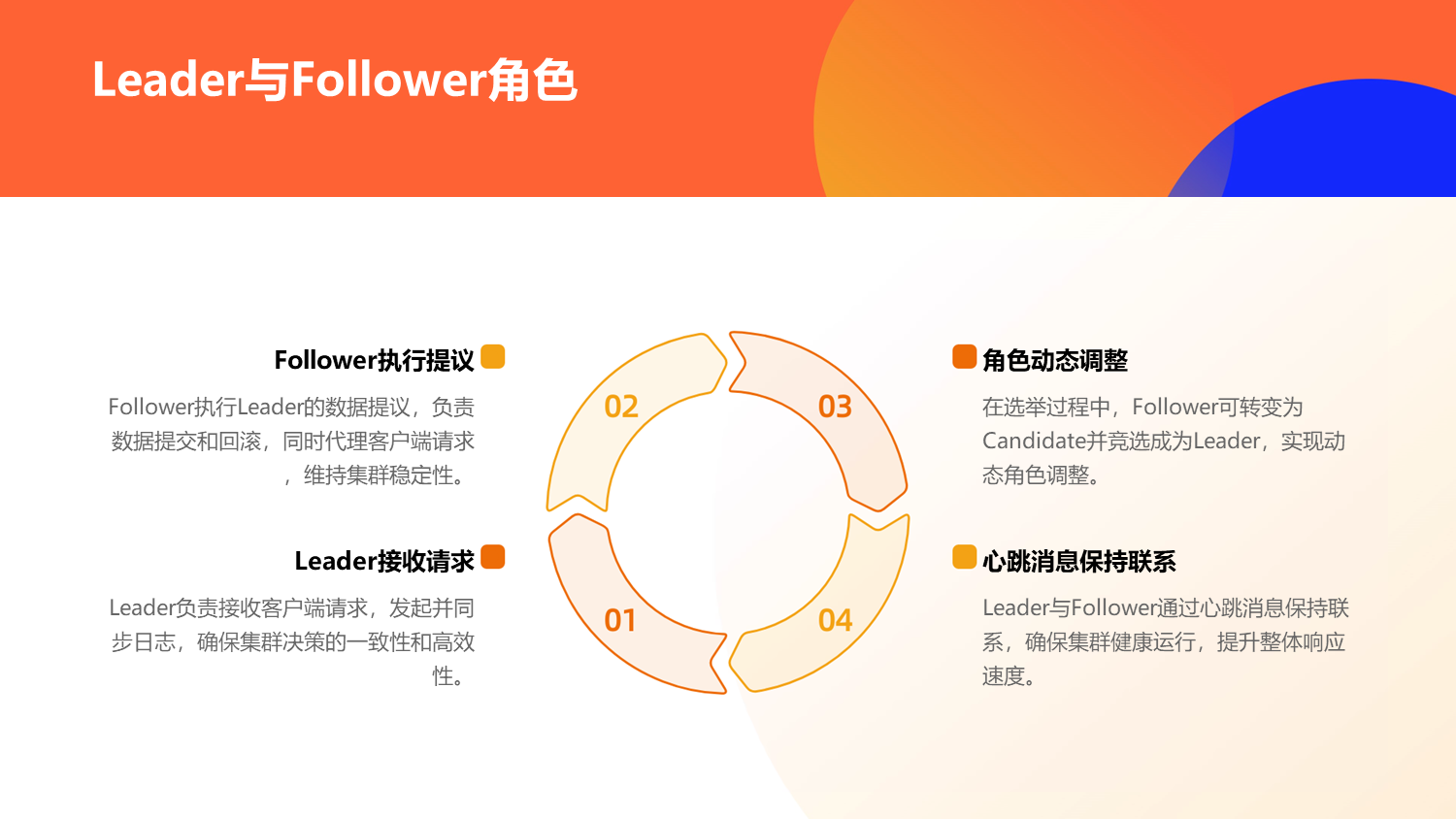
开发raftx目的是实现一个支持高并发的共识协议,这个核心目标,使得raftx脱离了raft的核心设计,因此说是raft协议扩展可能有一些不太准确,它更像paxos的另一种变体,paxos系列的共识协议,它们各个阶段的作用,都比较相似,只是叫法不同,因此,raftx参照raft的命名规则,也把节点分为Leader,Follower,Candidate,但是,在leader阶段中,分了两个小阶段:PREPARE与LEADER,这区别于raft,当节点当选为leader时,它会先进入PREPARE,并进行数据完整性检查与同步,完成后,进入LEADER阶段,这两个阶段都是leader,不会影响提案的处理,但是对于读取的数据,在PREPARE时,这个leader节点的数据可能处于不完整的状态,但是PREPARE状态持续的时间非常短,因为leader本身是所有节点中,数据链最长的节点,它同步缺失的数据,是最快的,更多情况下,leader在当选的时候,就已经是数据完整状态,无需同步。
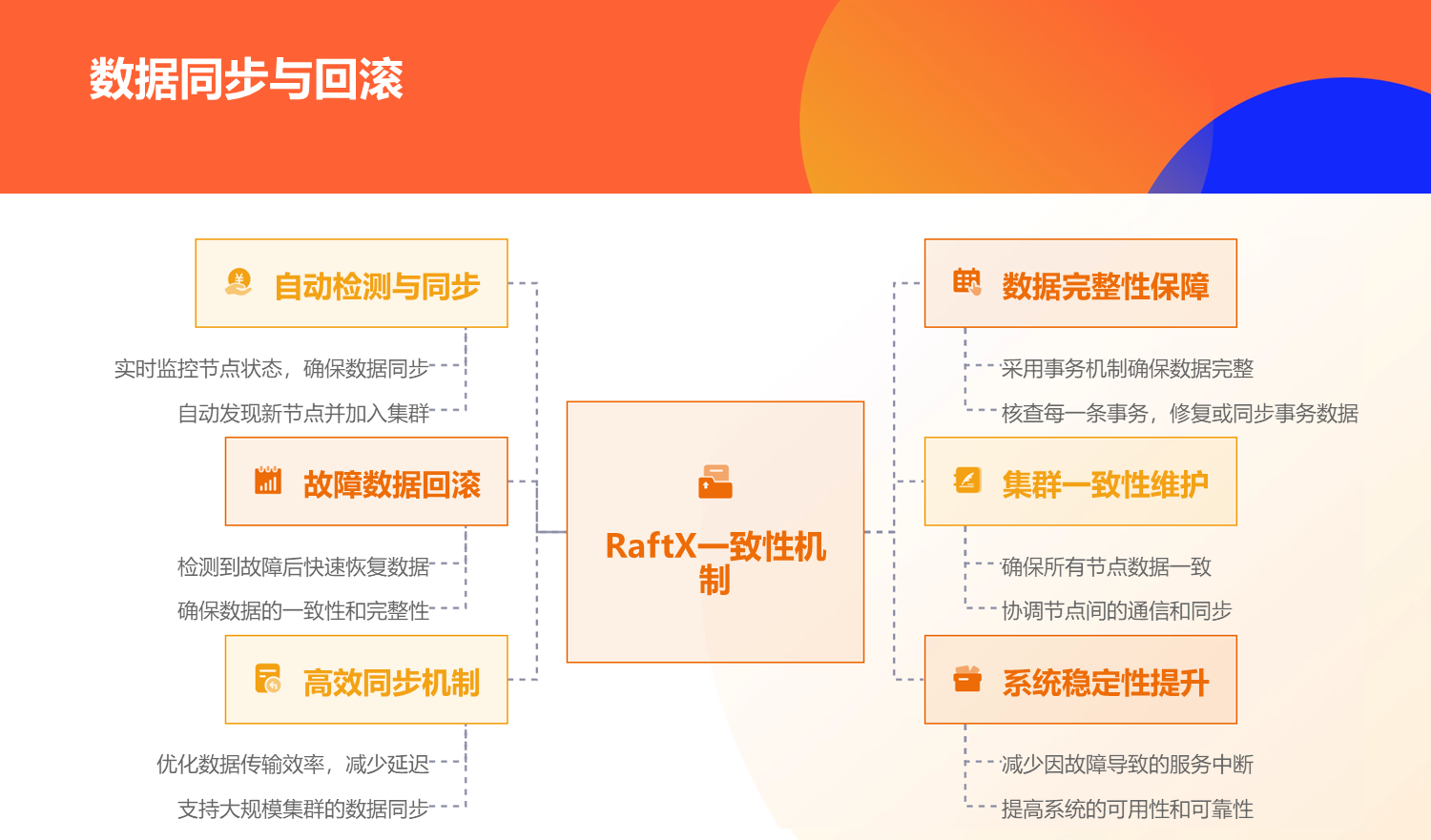
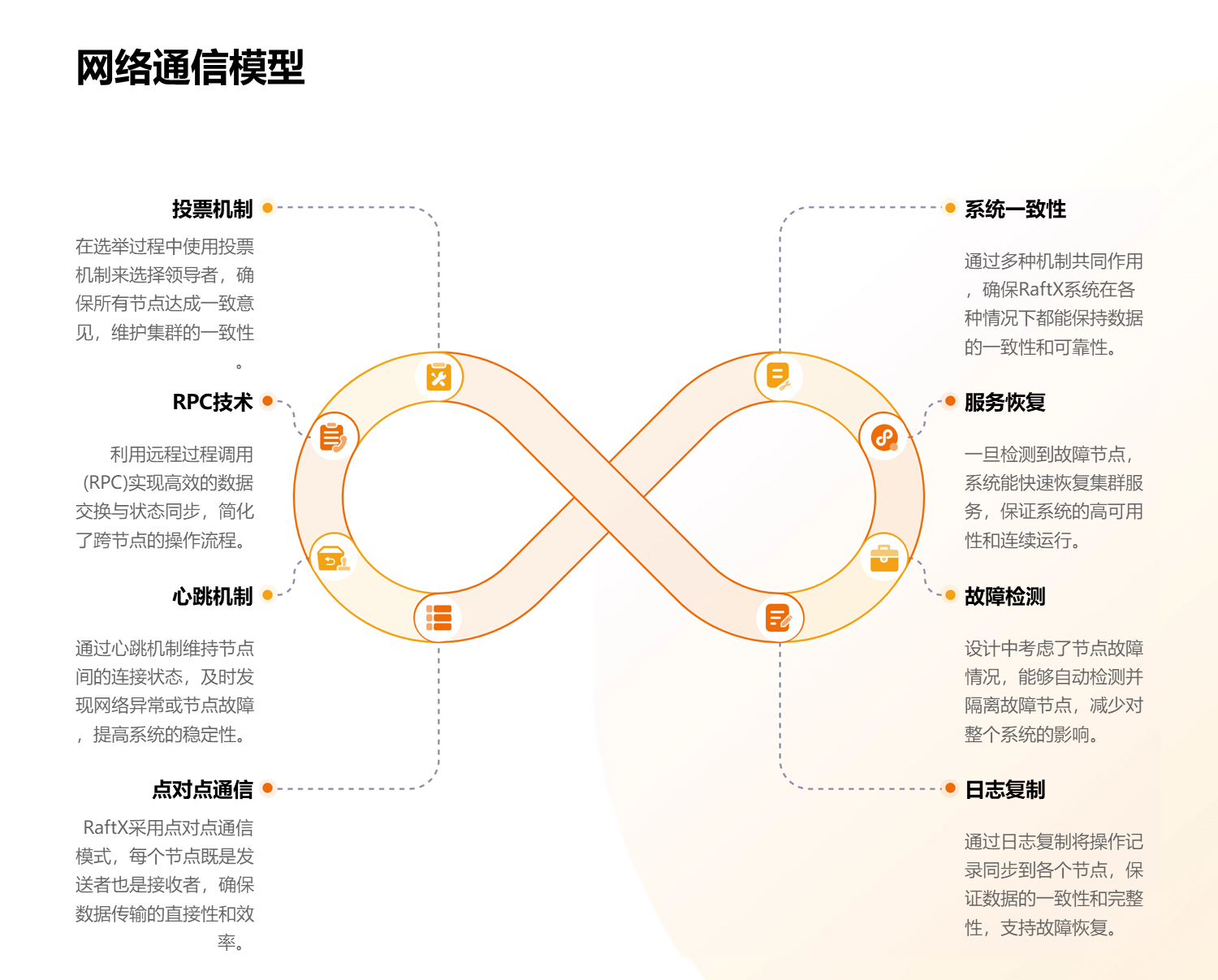
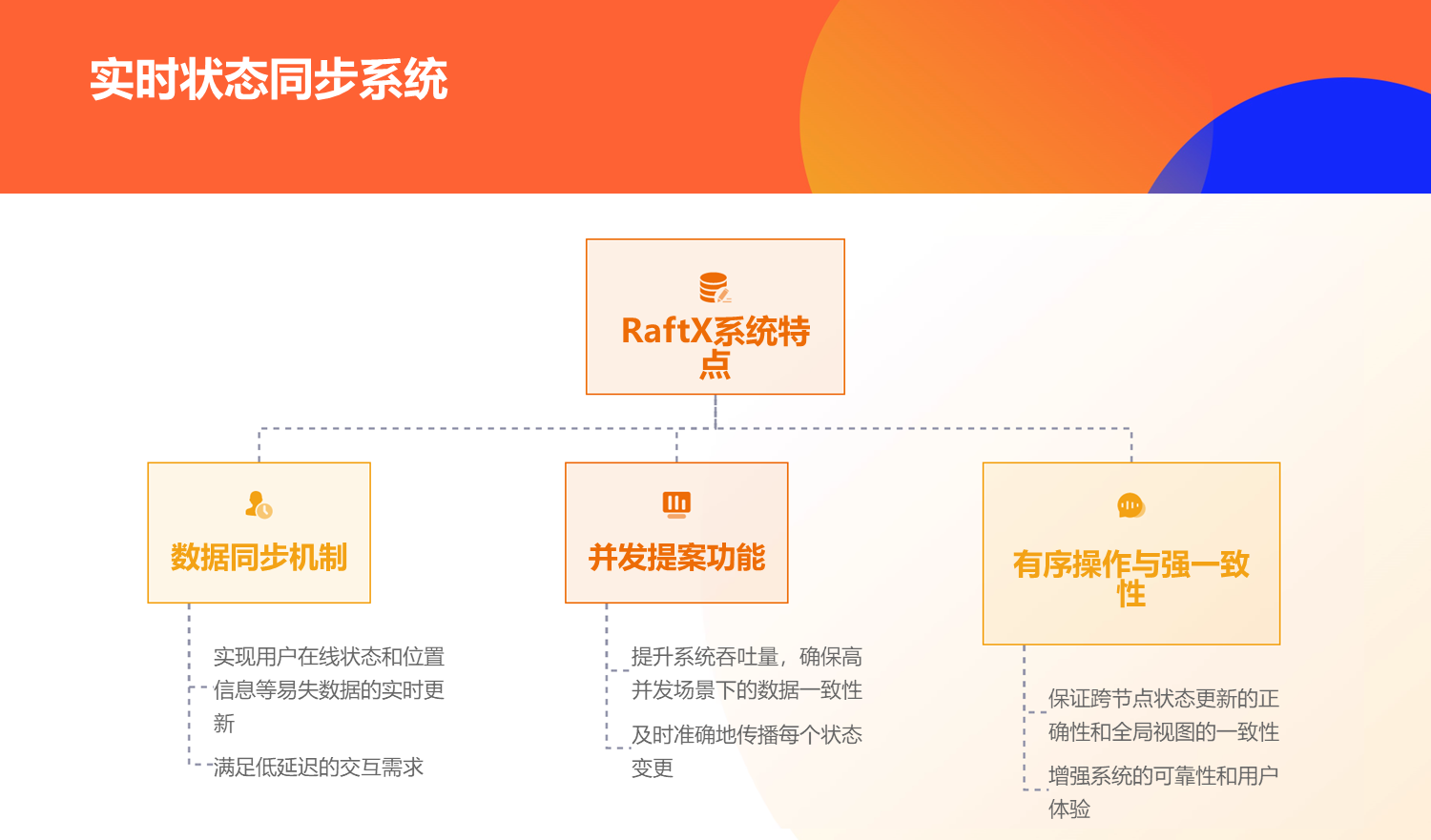
raftx由于支持高并发,它需要支持无序的并发提案,由于支持无序并发提案,它将出现raft可能不会出现的问题,也就是集群所有节点都缺数据的情况,因此,raftx需要像zab一样,支持所有节点都在一个时期内,向集群或向leader同步数据。因此raftx具备了multi-paxos的并发,raft的主要流程,zab的数据同步,在实现过程中,raftx同时实现了数据回滚,分布式易失性数据服务等功能,也优化了选举算法,解决raft在一个任期中可能出现的由于互投出现不断重选的情况。
Github地址
raftx 的功能特点