在计算机科学中,跳跃列表是一种数据结构。它使得包含n个元素的有序序列的查找和插入操作的平均时间复杂度都是O(logn),优于数组的O(n)复杂度。
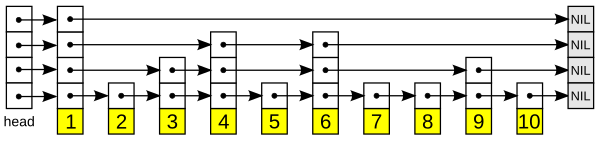
快速的查询效果是通过维护一个多层次的链表实现的,且与前一层(下面一层)链表元素的数量相比,每一层链表中的元素的数量更少(见右下角示意图)。一开始时,算法在最稀疏的层次进行搜索,直至需要查找的元素在该层两个相邻的元素中间。这时,算法将跳转到下一个层次,重复刚才的搜索,直到找到需要查找的元素为止。跳过的元素的方法可以是随机性选择[2]或确定性选择[3],其中前者更为常见。
| 跳跃列表 | |
|---|---|
| 类型 | 列表 |
| 发明时间 | 1989 |
| 发明者 | W. Pugh |
| 算法 | 平均 | 最差 | |
|---|---|---|---|
| 空间 | O(n) | O(n log n) | |
| 搜索 | O(log n) | O(n)[1] | |
| 插入 | O(log n) | O(n) | |
| 删除 | O(log n) | O(n) |
描述
一张跳跃列表的示意图。每个带有箭头的框表示一个指针, 而每行是一个稀疏子序列的链表;底部的编号框(黄色)表示有序的数据序列。查找从顶部最稀疏的子序列向下进行, 直至需要查找的元素在该层两个相邻的元素中间。
跳跃列表是按层建造的。底层是一个普通的有序链表。每个更高层都充当下面列表的“快速通道”,这里在第i层中的元素按某个固定的概率p(通常为12或14)出现在第i+1 层中。每个元素平均出现在11−p个列表中,而最高层的元素(通常是在跳跃列表前端的一个特殊的头元素)在log1/pn个列表中出现。
在查找目标元素时,从顶层列表、头元素起步。算法沿着每层链表搜索,直至找到一个大于或等于目标的元素,或者到达当前层列表末尾。如果该元素等于目标元素,则表明该元素已被找到;如果该元素大于目标元素或已到达链表末尾,则退回到当前层的上一个元素,然后转入下一层进行搜索。每层链表中预期的查找步数最多为1p,而层数为log1/pn,所以查找的总体步数为−logpnp,由于p是常数,查找操作总体的时间复杂度为O(logn)。而通过选择不同p值,就可以在查找代价和存储代价之间获取平衡。
跳跃列表不像平衡树等数据结构那样提供对最坏情况的性能保证:由于用来建造跳跃列表采用随机选取元素进入更高层的方法,在小概率情况下会生成一个不平衡的跳跃列表(最坏情况例如最底层仅有一个元素进入了更高层,此时跳跃列表的查找与普通列表一致)。但是在实际中它通常工作良好,随机化平衡方案也比平衡二叉查找树等数据结构中使用的确定性平衡方案容易实现。跳跃列表在并行计算中也很有用:插入可以在跳跃列表不同的部分并行地进行,而不用对数据结构进行全局的重新平衡。
| 一张跳跃列表的示意图。 每个带有箭头的框表示一个指针, 而每行是一个稀疏子序列的链表; 底部的编号框(黄色)表示有序的数据序列。 查找从顶部最稀疏的子序列向下进行, 直至需要查找的元素在该层两个相邻的元素中间。 |
实现细节
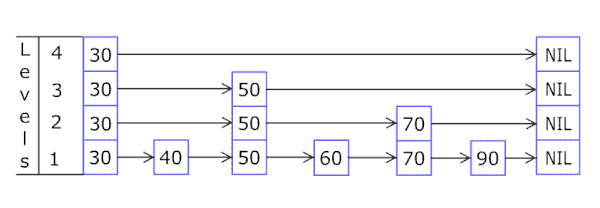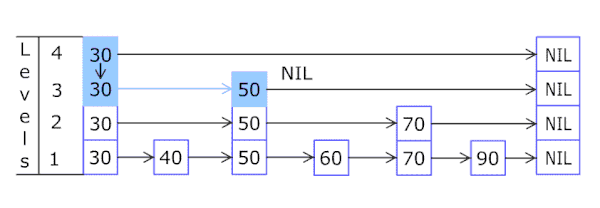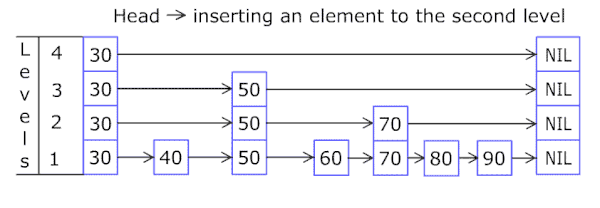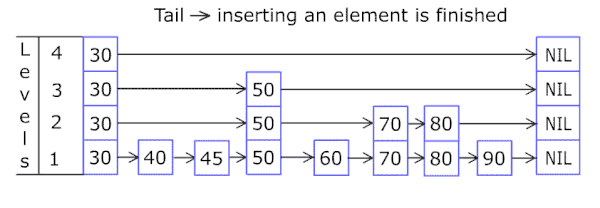 | 往跳跃列表中插入一个元素 |
因为跳跃列表中的元素可以在多个列表中,所以每个元素可以有多于一个指针。
跳跃列表的插入和删除的实现与普通的链表操作类似,但高层元素必须在进行多个链表中进行插入或删除。
跳跃列表的最坏时间性能具有一定随机性,但是可以通过时间复杂度为O(n)的遍历操作(例如在打印列表全部内容时)以无随机的算法重整列表的结构,从而使跳跃列表的实际查找时间复杂度尽量符合理论平均值O(logn)。
除了使用无随机算法之外,我们可以以下面的准随机方式地生成每一层:
make all nodes level 1
j ← 1
while the number of nodes at level j > 1 do
for each i'th node at level j do
if i is odd
if i is not the last node at level j
randomly choose whether to promote it to level j+1
else
do not promote
end if
else if i is even and node i-1 was not promoted
promote it to level j+1
end if
repeat
j ← j + 1
repeat
类似无随机版本,准随机重整仅在需要执行一个O(n)操作(访问每个节点)的时候伴随进行。
历史
跳跃列表由威廉·普发明。[2]发明者对跳跃列表的评价是:“跳跃列表是在很多应用中有可能替代平衡树而作为实现方法的一种数据结构。跳跃列表的算法有同平衡树一样的渐进的预期时间边界,并且更简单、更快速和使用更少的空间。”